Microsoft Hyperconvergence
1. Modèle Hyperconvergé de Microsoft
1.1 Introduction
-
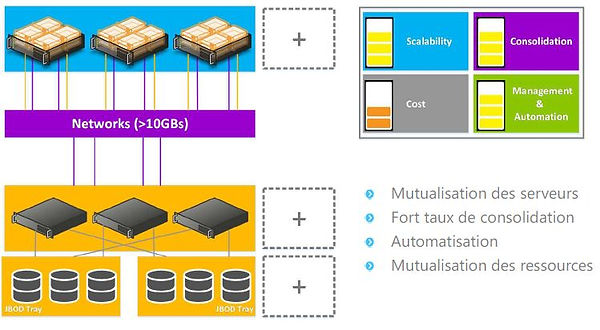
Composants basiques d’une infrastructure
-
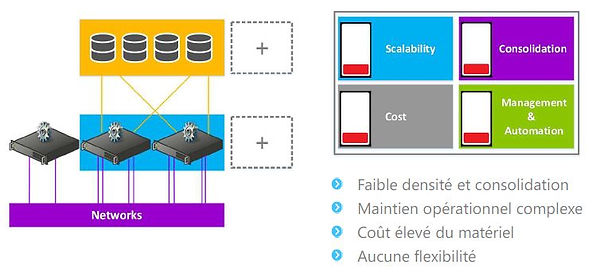
Le datacenter de "l’antiquité"
-
Le datacenter "moyenâgeux"
-
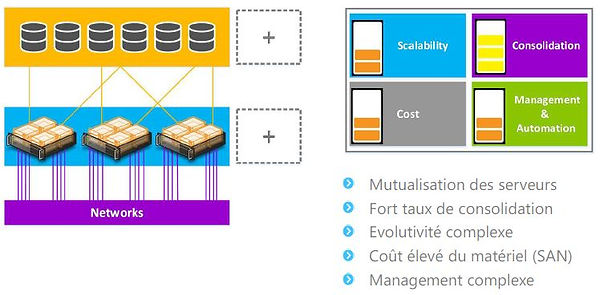
Le datacenter de la "renaissance"
-
Le datacenter du "monde moderne"
1.2 Avantages / Inconvénients
-
Avantages
-
Infrastructure
-
Réduction des équipements réseaux et de stockage nécessaires
-
Faible empreinte dans le datacenter
-
Moins de matériel = moins de panne
-
-
Flexibilité
-
Ajout d’un noeud = ajout CPU, RAM, Stockage
-
Monté en charge simplifiée
-
Automatisation du déploiement (logiciel)
-
-
Simplification
-
Simplification du réseau
-
Simplification du stockage
-
Solution basée sur du logiciel
-
-
-
Inconvénients
-
Dépendance stockage / hyperviseur
-
Ajout d’un noeud = ajout CPU, RAM, Stockage
-
Perte d’un noeud = perte d’un hyperviseur et d’une partie du stockage
-
Les ressources du noeud sont utilisés pour le calcul et le stockage
-
-
Contraintes matériels
-
Ne pas négliger le réseau
-
Attention aux cartes SAS / SATA (carte HBA)
-
Augmentation des ressources minimum requises par noeud
-
-
1.3 Fonctionnalités Requises
-
Hyperviseur
-
Hyper-V
-
Hyperviseur de Microsoft
-
Permet d’exécuter des machines virtuelles
-
-
Failover Clustering
-
Haute-disponibilité des VMs
-
Utile pour la couche stockage
-
-
Dépendances
-
Active Directory
-
DNS
-
-
-
Fonctionnalités de stockage
-
Failover Clustering
-
Utile pour la couche hyperviseur
-
Storage Spaces Direct
-
-
PRA (optionnel)
-
Storage Replica
-
Microsoft Azure
-
-
Dépendances
-
Active Directory
-
DNS
-
-
-
Fonctionnalités réseaux
-
Windows
-
Switch Embedded Teaming (recommandé)
-
-
Offload (optionnel) :
-
RDMA (RoCE ou iWARP) recommandé
-
Décharge du CPU pour les trafics réseau (durant Live Migration)
-
Noeud 1 intérroge la couche mémoire du Noeud 2 sans passer par l'OS
-
-
Datacenter Bridging si RoCE
-
-
Divers
-
Réseaux 10/25/40/100 GbE
-
Au moins deux NICs recommandés
-
-
-
Edition de Windows Server requise
2. Deep-Dive dans Storage Space Direct
2.1 Présentation de la stack hyperconvergé de Microsoft
-
Couche Computer :
-
Hyper-V
-
S'appuie sur Failover Clustering
-
-
Couche stockage
-
Storage Spaces Direct (S2D)
-
S2D intégré au cluster
-
-
Couche réseau
-
10/25/40/100 GbE ( 10 Gb est le minimum requis)
-
Basé sur SMB 3.11
-
Option: RDMA
-
Option: 2x vNICs
-
-
Couche matérielle (ex : serveur Lenovo System x3650 M5 ou Dell PowerEdge R730 XD)
-
CPU
-
RAM
-
Disques
-
Cartes réseaux
-
Cartes HBA
-
-
Couche stockage
-
Storage Spaces Direct
-
Software Storage Bus (voir tous les disques présents dans chacun des LUN)
-
Storage Pool (permet d'agréger tous les disques)
-
Storage Spaces (disques virtuels qui hébergent les données)
-
-
Failover Clustering : CSV
-
2.2 Pré-requis réseaux
-
Bande passante requise (10 GbE minimum)
-
Pour les communications intra-cluster
-
Supporte aussi le 25/40/100 GbE
-
Nécessaire pour replication et accès aux données
-
Les SSDs sont très consommateurs
-
-
Remote Direct Memory Access
-
RDMA (ex Noeud 1 intérroge la couche mémoire du Noeud 2 sans passer par l'OS)
-
Réduit la consommation CPU
-
Réduit la latence
-
Augmente les débits
-
Fonctionnalité recommandée mais pas obligatoire
-
-
Implémentation de RDMA supporté
iWARP utilise le protocole TCP (Transmission Control Protocol) comme protocole de transport, tandis que RoCE utilise le protocole UDP (User Datagram Protocol).-
iWARP (internet Wide Area RDMA Protocol)
-
Solution Plug & Play
-
Protocole de réseau informatique qui permet l’accès direct à la mémoire à distance (RDMA) sur les réseaux IP (Internet Protocol)
-
Il en résulte un transfert de données hautes performances et à faible latence, ce qui est particulièrement utile pour des applications telles que le calcul haute performance, le cloud computing et les systèmes de stockage.
-
-
RoCE (RDMA over Converged Ethernet)
-
Solution nécessitant une configuration de bout en bout (côté OS et côté switch)
-
DataCenter Bridging requis
-
Data Center Bridging englobe une série de fonctionnalités permettant d'améliorer la capacité des réseaux Ethernet classiques pour gérer le trafic, en particulier dans les environnements où le volume de trafic réseau et le taux de transmission sont élevés.
-
Il faut gérer la QoS pour laisser suffisament de bande passante au trafic de stockage sur le réseau.
-
-
-
-
-
Exemple de matériel
-
Cartes réseaux
-
Mellanox Connectx4 pro (RoCE)
-
Chelsio T6225-CR (iWARP)
-
Intel X710 series (Non RDMA)
-
-
Switches
-
Mellanox SN2100
-
Sur 1U on peut mettre 2 SN2100
-
16 ports à 100 GbE
-
Chaque port peut-être divisé en 4 ports 25 Gb ou 2 ports 50 Gb
-
Accès à 64 ports 25 Gb ou 32 ports 50 Gb
-
-
-
Lenovo RackSwitch G8272
-
Cisco Catalyst 3xxx series
-
-
-
Design réseau du cluster
-
Recommandations Microsoft pour les Clusters
-
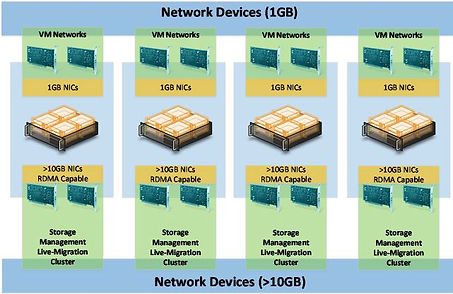
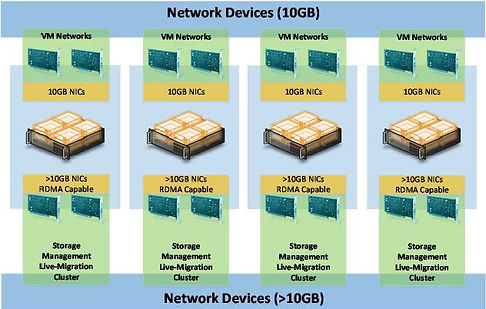
1x carte physique (pNIC) ou 1x Carte virtuelle (vNIC) pour le management
-
2x pNIC ou 2x vNIC pour les flux clusters (Heartbeat, SMB, Live-Migration etc.)
-
-
Simplified SMB MultiChannel
-
Système activé automatiquement dans les clusters Windows Server 2016
-
Reconnaissance automatique des pNIC ou vNIC sur le même switch / sous-réseau
-
Une seule IP est configurée pour chaque point d’accès cluster (agrégat de cartes réseaux)
-
-
Concernant les flux SMB
-
SMB Multichannel configuré automatiquement
-
SMB utilisera par défaut les pNIC ou vNIC où les metrics sont les plus faibles
-
-
-
Réseau 1GB + Réseau 10GB
-
Réseau 10GB + Réseau 10GB
-
Réseau > 10GB convergé
2.4 Pré-requis serveurs et stockage
-
Prérequis serveurs
-
Nombre de noeuds par cluster
-
Minimum 2 serveurs
-
Maximum 16 serveurs
-
-
CPU
-
Processeur Intel Nehalem ou plus récent
-
Recommandé 2x Intel Xeon par serveur
-
-
Mémoire
-
4GB de mémoire par TB de cache
-
Ex: avec 2x 1TB de cache: 2 x 1 x 4096MB = 8192MB
-
-
-
Prérequis carte HBA
-
Cartes supportées
-
Carte HBA simple en mode pass through JBOD (SAS ou SATA)
-
SCSI Enclosure Service (SES) (SAS ou SATA) : allumer les leds pour détecter les pannes, et localiser les disques
-
Les disques doivent être Direct-Attached et présenter un ID unique (disque rattaché à un seul serveur)
-
Non supportées : Carte RAID, Carte SCSI, disque SAN/NAS et MPIO
-
-
Exemple de cartes
-
Lenovo N2215
-
Dell HBA330
-
-
-
Prérequis stockage
-
Type de disques
-
NVMe, SAS ou SATA et physiquement attaché à un seul serveur
-
Disque entreprise avec protection contre les coupures de courant
-
Disque de cache : minimum 5 Disk Write Per Days (DWPD)
-
Utiliser un disque et/ou carte HBA dédié pour l’OS
-
-
Configuration dans le cluster
-
Recommandé : tous les serveurs ont la même configuration
-
Tous les serveurs doivent avoir les mêmes types de disques
-
Ajout de disques de capacité en suivant un multiple du nombre de disque de cache
-
-
-
Minimum de disques requis
S’il y a un système de cache :-
au moins deux disques de cache
-
Au moins quatre disques de capacité
-
2.5 Fonctionnement du Software Storage Bus
-
Qu’est ce que le Software Storage Bus ?
-
Software Storage Bus
-
Bus de stockage virtuel étendu aux noeuds du cluster (chaque noeud à l'intérieur du cluster aura accès à ce bus logiciel)
-
Permet à tous les noeuds de voir tous les disques
-
-
Protocole
-
Utilisation de SMB3
-
Permet de s’appuyer sur SMB MultiChannel (agrégat de cartes réseaux) , SMB Direct (activation RDMA)
-
-
Gestion de la bande passante
-
Algorithme d’accès équitable entre les noeuds
-
Priorité des IO applicatives (VM) par rapport aux IO systèmes
-
-
-
Fonctionnement
-
ClusPort
implémente un adaptateur de bus hôte/carte de bus hôte (HBA) virtuel(le) qui
permet au nœud de se connecter aux disques sur tous les autres serveurs du cluster. -
ClusBlft
implémente la virtualisation des disques et boîtiers
de chaque serveur pour la connexion à ClusPort
sur d’autres serveurs.
-
2.6 Fonctionnement du système de cache
-
Système de cache
-
Activé par défaut
-
Surtout pour un serveur avec stockage mix
-
Cache en lecture/écriture ou écriture
-
Le disque le plus rapide est le disque de cache
-
-
Déploiement manuel
-
Pour des déploiements personnalisés
-
Cache réglable par PowerShell
-
Possibilité de régler le type de cache manuellement
-
-
-
Fonctionnement
-
Type de déploiement
-
Déploiement All flash
-
Full NVMe => pas de cache
-
Full SSD => pas de cache
-
NVMe + SSD / NVMe + NVMe / SSD + SSD = Cache en écriture
-
-
Déploiement hybride
-
SSD + HDD => cache en lecture / écriture
-
NVMe + HDD => Cache en lecture / écriture
-
SSD + (SSD+HDD) => Cache en écriture pour SSD et Cache en lecture et écriture pour HDD
-
NVMe + (SSD+HDD) => Cache en écriture pour SSD et Cache en lecture et écriture pour HDD
-
-
-
Ratio disques de cache / capacité
-
Association disque cache / capacité
-
Géré par le système
-
Disques de capacité associés en Round Robin aux disques de cache
-
-
Ratio à respecter
-
Chaque disque de cache doit avoir le même nombre de disque de capacité
-
Ratio 1:1 à 1:12 et au delà
-
-
-
Résilience du cache
Si perte d'un disque de cache,
les disques de capacité vont être réassociés au disque de cache
2.7 Déploiement d'un cluster Storage Spaces Direct
-
Rappel du LAB
-
Machines virtuelles
-
Gen 2, 4 vCPU, 8GB de mémoire statique et 2x vNICs
-
8x disques virtuelles de 100GB (en dynamique)
-
-
Hyperviseur
-
Hyper-V sous Windows Server 2016
-
Nested Hyper-V pour les VMs
-
-
-
Paramètrage VMs du LAB
-
Disques Virtuels 100Go
-
Cartes Réseaux
-
1 carte Management
-
2 cartes connexion aux Cluster 1 et 2
-
-
Activation Nested Hyper-V
-
Récupérer les VMs dans le Cluster
-
Activation Instructions Etendues pour la virtualisation
get-vm *VMHCI* -ComputerName Cluster-Hyv01 | Set-VMProcessor -ExposeVirtualizationExtensions $True
-
-
Creation Switch Embedded Teaming (serveur physique)
New-VMSWitch -Name SW-10G -NetAdapterName "NIC1","NIC2" -EnableEmbeddedTeaming $True -AllowManagementOS $False
Add-VMNetworkAdapter -SwitchName SW-10G -ManagementOS $True -Name Management
Add-VMNetworkAdapter -SwitchName SW-10G -ManagementOS $True -Name Cluster-01
Add-VMNetworkAdapter -SwitchName SW-10G -ManagementOS $True -Name Cluster-02
-
Activation du RDMA : Enable-NetAdapterRDMA "*Cluster*"
-
-
Création du Cluster
-
Install Hyper-V & Cluster
Install-WindowsFeature Hyper-V, Failover-Clustering -IncludeManagementTools -Restart -
Test du cluster
Test-Cluster -Node "VMHCI01", "VMHCI02", "VMHCI03", "VMHCI04" -Include "Storage Spaces Direct", Inventory,Network,"System Configuration"
-
Creation du Cluster
New-Cluster -Node "VMHCI01", "VMHCI02", "VMHCI03", "VMHCI04" -Name Cluster-Hyv02 -StaticAddress 10.10.0.52 -NoStorage
-
-
Activation Storage Spaces Direct
$Cim = New-CimSession Cluster-Hyv02
Enable-ClusterS2D -CimSession $CIM
2.8 Introduction aux storage pools et aux storage spaces
-
Storage Pool et Storage Spaces
-
Storage Spaces
-
Résilience
-
La résilience est géré par le
Storage Spaces -
Mirroring, Parity ou les deux
-
-
Notion
-
Colonne: nombre de disques participant au Storage Spaces
-
Interleave: taille du block (par défaut 256 Ko)
-
-
Fonctionnement dans le cluster
-
S’appuie sur Cluster Shared Volume (CSV) pour éviter les accès concurrents
-
Les VMs seront hébergées dans le CSV
-
-
2.9 Introduction aux systèmes de résilience
-
Fault Domain Awareness
-
Un Fault Domain (FD) est une collection de matériels qui partagent le même point de défaillance
-
Définition de votre infrastructure avec 4 types :
-
Site
-
Rack
-
Chassis
-
Noeuds
-
-
Chaque type correspond à un FD
-
Permet de la tolérance de panne comme dans Azure
-
-
Mirroring
-
Mirroring
-
Copie de la donnée initiale une fois ou deux
-
Système le plus performant
-
Slab : 256MB
-
-
Deux modes
-
2-Way Mirroring (2 FD ou plus) – 50% utile
-
3-Way Mirroring (3 FD ou plus) – 33% utile
-
Bonne pratiques
-
Système recommandé pour de la VMs
-
En production : 3-Way Mirroring
-
-
-
Parity
-
Parity
-
Créer des symboles de parité
-
Système le plus efficace
-
Slab: 256MB
-
Le pilote Storage Spaces divise chaque disque d'un pool en morceaux de 256 Mo, appelés « slab ».
-
Les slab sont ensuite combinées pour produire des disques virtuels simples, miroirs ou de parité.
-
Enfin, les disques virtuels sont partitionnés de la même manière que les disques normaux."
-
-
-
Deux modes (4 FD ou plus)
-
Simple Parity – jusqu’à 80%
-
Dual Parity – jusqu’à 80%
-
-
Bonne pratiques
-
Système recommandé pour archivage ou backup
-
En production: Dual Parity
-
-
-
Multi-Resilient Virtual Disks
-
Multi-Resilient Virtual Disk
-
Deux tiers dans un virtual disks
-
ReFS obligatoire
-
Non recommandé pour de la VMs
-
-
Efficacité
-
Deux tiers (mirroring et parité).
-
Données chaudes -> Mirroring (33% utile)
-
Données froides -> Parité (jusqu’à 80% utile)
-
-
Performant
-
Ecriture dans le tier chaud
-
Tiering dans le tier froid
-
-
-
Résumé
2.10 Système de fichiers recommandé pour Storage Spaces Direct
-
ReFS
-
Système de fichiers amélioré avec WS 2016
-
Apporte les opérations VHDX accélérées
-
-
Trafic redirigé sur le réseau
-
Storage Spaces Direct va redirigé la majorité du trafic sur le réseau
-
ReFS approprié uniquement avec cet usage uniquement
-
-
Alignement
-
Il est recommandé de formater le volume en ReFS et en 4K
-
2.11 Déploiement d'un Storage Pool et de Storage Spaces
-
Vue du Storage Pool
-
Vue des 8 disques par Noeud
-
Vue de la capacité totale du Pool
-
-
Récupération d'informations
-
A partir d'un serveur distant
-
Register-StorageSubSystem –ComputerName cluster-hyv02.homecloud.net –ProviderName *
-
-
Récupération d'information du Cluster: Get-StorageSubSystem
-
Get-StorageSubSystem -FriendlyName "*Cluster-Hyv02*"
-
Get-StorageSubSystem -FriendlyName "*Cluster-Hyv02*" | Get-StoragePool
-
-
-
Création de Volumes
-
3-Way Mirroring
New-Volume -StoragePoolFriendlyName "*Cluster-Hyv02*" `
-
-
-FriendlyName "3wMirroring" `
-NumberOfColumns 4 `(4 disques utilisés pour la donnée initiale + 4 pour Réplica1 + 4 pour Réplica2)
-PhysicalDiskRedundancy 2 `(Cette valeur représente le nombre de disques physiques défaillants pouvant tolérer le disque virtuel sans perte de données)
-ResiliencySettingName Mirror `
-FileSystem CSVFS_REFS `
–Size 50GB (La consommation effective sera de 150 Go en 3-way Mirroring)
-
3-Way Parity
-
New-Volume -StoragePoolFriendlyName "*Cluster-Hyv02*" `
-FriendlyName "DualParity" `
-NumberOfColumns 4 `
-ResiliencySettingName Parity `
-PhysicalDiskRedundancy 2 `
-FileSystem CSVFS_REFS `
–Size 50GB
2.12 Ajouter / supprimer un noeud
-
Ajout d'un serveur
-
Configuration identique aux autres serveurs (CPU/Ram/Disks)
-
Installation Rôles système
-
-
Ajout d'un Noeud
-
Test du Cluster
-
-
Test-Cluster -Node "VMHCI01", "VMHCI02", "VMHCI03", "VMHCI04", "VMHCI05" -Include "Storage Spaces Direct", Inventory,Network,"System Configuration" -Cluster Cluster-Hyv02
-
Ajout du Noeud au Cluster
-
Add-ClusterNode -Name VMHCI05 -Cluster Cluster-Hyv02
-
2.13 Gérer la QoS des disques de machines virtuelles
-
Distributed Storage QoS
-
Politiques de QoS
-
Types de politique
-
Monitoring
2.14 Gérer les mises à jour du cluster ( Cluster-Aware Updating )
-
Présentation
-
Fonctionnalité automatisée qui vous permet de mettre à jour les serveurs dans un cluster de basculement avec peu ou pas de perte de disponibilité pendant le processus de mise à jour.
-
L'installation s'exécute à une heure planifiée
-
Tour à tour les nœuds vont installer les mises à jour
-
Lorsqu'un nœud redémarre pour finaliser l'installation,
les rôles qu'il héberge (exemple : VM) sont basculés sur
un autre nœud du cluster -
Cette fonctionnalité est compatible avec un cluster à 2 noeuds
-
-
Lorsque la phase de mise à jour se déclenche sur votre cluster, l'ordonnancement est effectué par un nœud qui assure le rôle de coordinateur. Lorsque le coordinateur doit à son tour redémarrer, c'est un autre nœud qui assume cette responsabilité.
-
-
Configuration
-
Connectez-vous sur un nœud de votre cluster avec un compte étant Administrateur du domaine.
Ensuite, dans les outils d'administration de votre serveur, ouvrez : Mise à jour adaptée aux cluster (ou Cluster-Aware Updating). -
Sélectionnez votre cluster et établissez la connexion.
-
Lancez l'Analyse de la disponibilité du Cluster
-
Configuration de Mise à jour Automatique
-
Activez le mode "Cluster Aware Updating" sur ce cluster en cochant l'option comme ci-dessous :
-
En fonction de vos besoins, il utile de planifier
l'installation des mises à jour.
-
Sur l'étape suivante, vous pouvez personnaliser la configuration avec de nombreux paramètres.
Ce qui est intéressant c'est de passer sur "True" (vrai) le paramètre "RequireAllNodesOnline" pour que le processus de mise à jour s'effectue uniquement si tous les noeuds sont en lignes, ça évitera de se retrouver en situation compliquée lorsque le noeud redémarre pour finaliser l'installation des updates.
-
-
Appliquer les Mise à jour
-
-
3. Troubleshooting et Monitoring
3.1 Monitoring de la solution avec Health Service
-
Health Service
-
Health Service
-
Nouveau service dans Failover Clustering dans WS2016
-
Activé uniquement quand S2D est activé
-
Rassemble les metrics et les alertes en temps réel des noeuds du cluster
-
-
API
-
Informations accessibles depuis un seul point d’entrée
-
PowerShell, .NET, C# etc.
-
-
-
Metrics
-
Health service met à disposition des rollups monitors
-
Pour qu’un noeud soit sain, les moniteurs enfants doivent être sains
-
Dans la prochaine version de Health Service, le service sera intelligent:
-
Un noeud qui perd un disque provoque une erreur sur le moniteur noeud
-
Cependant le cluster affiche qu’un “Warning” car il a assez de noeud pour encore faire marcher le service
-
-
-
Incidents
-
Temps réel
-
Les incidents sont traités en temps réel
-
Affichage de la source de la panne
-
-
Exemple de panne
-
Carte réseau déconnectée
-
Serveur injoignable (maintenance ou panne sérieuse)
-
Un disque est absent
-
Il n’y a plus d’espace libre sur le Storage Pool
-
-
-
Solution de monitoring
3.2 Remplacer un disque défectueux
-
Récupérer Information du Stockage du Cluster
Get-StorageSubSystem "*Cluster-hyv02*" | Get-physicaldisk
-
Détecter un disque non "sain"
Get-StorageSubSystem "*Cluster-Hyv02*" | Get-PhysicalDisk |? HealthStatus -notlike "Healthy"
-
Récupération UniqueID Disque Physique
$PhysicalDisk = Get-StorageSubSystem "*Cluster-Hyv02*" | Get-PhysicalDisk |? uniqueID -like "600224804ED55DA0BDE3C6827283AE0A"
-
Retirer le disque défectueux
Set-PhysicalDisk -InputObject $PhysicalDIsk -Usage Retired
-
Activer les LED sur le disque Physique
Enable-PhysicalDiskIdentification -UniqueId "600224804ED55DA0BDE3C6827283AE0A"
-
Changement du Mode -> Automated Seleted
Set-PhysicalDisk -InputObject $PhysicalDIsk -Usage AutoSelect
3.3 Premiers gestes en cas d'incident
-
Vérifier les Events dans le Gestionnaire de Basculement
-
Vérifier dans l'Observateur d'Evènements
-
Vérification SMB Multi-Channel
-
Vérification Santé du Cluster
-
Vérifier Exécution des Jobs
Get-StorageSubSystem "*Cluster-hyv02*" | Get-StorageJob
-
Vérifier les Storage Spaces
-
Etat des Disques Virtuel
Get-StorageSubSystem "*Cluster-hyv02*" | Get-VirtualDIsk
-
Etat des Pools
Get-StorageSubSystem "*Cluster-hyv02*" | Get-StoragePool
-
Etat des Disques Physiques
-
Get-StorageSubSystem "*Cluster-hyv02*" | Get-physicaldisk
-
Réparation Disques Virtuels
Get-VirtualDisk -FriendlyName Hybrid | Repair-VirtualDisk
-
Réquilibrer les données sur tous les Noeuds
Optimize-StoragePool -FriendlyName "*Cluster-hyv02*"-
Rééquilibre les allocations d'espaces dans un pool vers des disques avec une capacité disponible.
-
Si vous ajoutez de nouveaux disques ou domaines de pannes, cette opération permet de déplacer les allocations d'espaces existantes vers ces derniers, et l'optimisation améliore leurs performances.
-
























































































4. Plan de reprise d'activité
4.1 Introduction à Storage Replica
-
Storage Replica
-
Réplication synchrone / asynchrone
-
Augmenter la résilience
-
Réplication au niveau bloc d'un cluster à un autre
-
Site Actif / Passif
-
-
Solution complète
-
Gestion simplifiée
-
-
Scénarios possibles
-
Stretch Cluster
-
Cluster Étendu entre 2 Sites
-
Impossible avec Storage Spaces Direct
-
Disponible si solution de stockage "au dessus" est du SAN ou du NAS
-
-
Cluster To Cluster
-
Le + utilisé avec S2D
-
Mise en oeuvre PRA avec Site Actif/Passif
-
-
Server To Server : 2 Servers en Stand-Alone
-
Server To Self
-
Réplication à l'intérieur d'un seul serveur
-
Ex : d'un volume à un autre
-
-
-
Modes de réplication
-
Prérequis
-
Latence réseau
-
Moins de 5 ms pour le mode synchrone
-
Latence élevée pour le mode asynchrone
-
-
Bande passante
-
Performance et taille du volume de log
-
-
Mise en place
-
Ajout 3ème Cluster (identique Cluster 2)
-
Installation RSAT Storage Replica : Install-WindowsFeature RSAT-Storage-Replica
-
Installation Feature Storage Replica sur les 8 VMs (2 clusters) : Install-WindowsFeature Storage-Replica
-
Création d'un Volume de 100 Go sur les 2 clusters (3 way-mirroring)
New-Volume -StoragePoolFriendlyName "*Cluster-Hyv02*" `
-FriendlyName "Storage-01" `
-NumberOfColumns 4 `
-PhysicalDiskRedundancy 2 `
-ResiliencySettingName Mirror `
-FileSystem CSVFS_REFS `
–Size 100GB
New-Volume -StoragePoolFriendlyName "*Cluster-Hyv03*" `
-FriendlyName "Storage-01" `
-NumberOfColumns 4 `
-PhysicalDiskRedundancy 2 `
-ResiliencySettingName Mirror `
-FileSystem CSVFS_REFS `
–Size 100GB
-
Création d'un Volume de LOG
-
Autoriser les Accès des Noeuds aux Clusters
Grant-SRAccess -ComputerName VMHCI01 -Cluster Cluster-hyv03
Grant-SRAccess -ComputerName VMHCI06 -Cluster Cluster-hyv02
-
Création Lien de Réplication
-
Inverser Lien de Réplication
Set-SRPartnership -NewSourceComputerName Cluster-hyv03 `
-SourceRGName Group2 `
-DestinationComputerName Cluster-hyv02 `
-DestinationRGName Group1
-
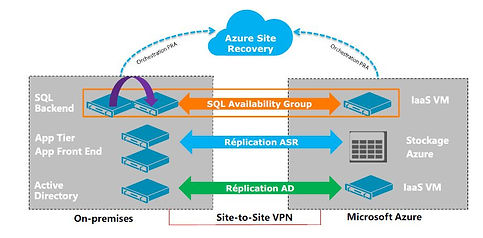
4.2 Introduction à Azure Site Recovery
-
Azure Site Recovery
-
Fonctionnalités
-
Protection et réplication automatisées des machines virtuelles VMWare ou Hyper-V et de machine physiques
-
Orchestration du PRA à l’aide de plans de récupération personnalisables
-
Azure Site Recovery peut utiliser Azure Automation pour automatiser des tâches lors de l’exécution du PRA
-
Possibilité de tester un plan de récupération sans impact sur la production
-
-
Pré-requis
-
Nécessite un compte Microsoft Azure
-
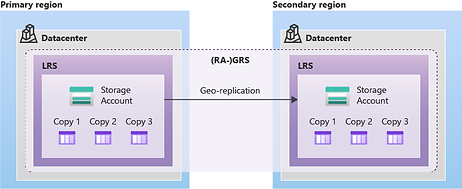
Nécessite au moins un compte de stockage dans la même région que l’instance ASR
-
Un réseau virtuel configuré est nécessaire pour interconnecter les VMs qui ont basculées.
Ce réseau virtuel doit être dans la même zone géographique que l’instance ASR
-
-
-
Exemples de scénario
-
Scénarios disponibles
-
Configuration Azure Site Recovery
-
Connexion au Compte Azure
-
Création Compte de Stockage
-
Création Réseau Virtuel
-
Création Azure Site Recovery
-
-
Recovery Vault
-
Resource Group/Overview/ASR
-
Sélectionner REPLICATE
-
Source Environment -> 1st Prepare Infrastructure : Getting Started / Site Recovery / Step 1 : Prepare Infrastructure
-
-
-
Prepare Infrastructure
-
Protection Goal
-
On Premise (Hyper-V) To Azure
-
Création Hyper-V Site
-
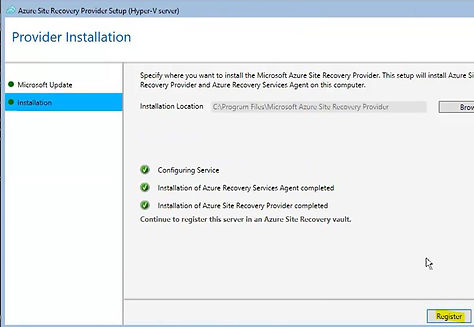
Ajout Hyper-V Servers
-
Download Installer for Microsoft Azure Site Recovery Provider ( à copier sur chaque Noeud)
-
Download the Vault Registration Key to register the Hosts in a Hyper-V Site ( à copier sur chaque Noeud)
-
-
-
Source (attendre remontée des Noeuds : 15 à 30 min)
-
Target
-
Replication Settings
-
Deployment Planning
-
-
Replication Application
-
Source
-
Target
-
Virtual Machines
-
Properties
-
Replication Settings
-
-
Recovery Plans
-
-
5. Conclusion
-
Hyperconvergence : les atouts
-
Simplicité
-
Facile à déployer
-
Facile à administrer
-
-
Flexibilité
-
Ajout / suppression d’un noeud rapide
-
Ajout d’un noeud = ajout de CPU et de RAM
-
-
Orienté Cloud
-
Suivi de la montée en charge plus facile
-
Systèmes de gestion de QoS pour plusieurs SLA
-
-
-
Hyperconvergence : attention
-
Evitez les économies sur :
-
Les équipements réseaux (y compris les NICs)
-
La qualité des équipements de stockage
-
-
Ne pas choisir cette solution lorsque:
-
Le réseau n’est pas adapté
-
Si les besoins stockage sont plus élevés que CPU
-
-
Le design
-
Passer du temps sur le design avant d’acheter
-
Bien calculer le stockage utile restant
-
-